最近、PostgreSQL上でデータ分析処理をよく行うようになってきました。また、いろいろなところでSSDも使うようになってきました。
PostgreSQLとデータ分析とSSD、という組合せを考えた時、どのようにチューニングするのが望ましいのか、あるいはどのようなチューニングができるのか、個人的にはまだまだ試行錯誤中だったりします。
SSDはハードディスクと比べてブロックサイズが大きいという特徴があります。また、DWH系のデータベースでは大きいブロックサイズを使うとパフォーマンス上のメリットがある、と言われています。
今回は、SSD上でPostgreSQLを使ってデータ分析系の処理を行う時に、データブロックのサイズを変えるとクエリのパフォーマンスにどのような影響を与えるのか、実際にクエリを実行しながら見ていきます。
■ブロックサイズの変更方法と確認方法
PostgreSQLでデータブロックのサイズを変更するには、PostgreSQLのブログラムバイナリをビルドする際にブロックサイズを指定する必要があります。
具体的にはconfigureスクリプトのオプションに--with-blocksizeというオプションを与えて、ここでブロックサイズを指定します。
./configure --prefix=/usr/local/pgsql --with-blocksize=32configureで指定できるブロックサイズはキロバイト単位で指定する必要があり、指定できる値は「1, 2, 4, 8, 16, 32」のいずれかになります。これより大きいサイズにするためには、コードをハックする必要があります(ちょっと変えただけでは make check でエラーになりました・・・)
また、稼働しているPostgreSQLのデータブロックのサイズを確認するためには、SQLコマンドとしてSHOW block_sizeを実行します。
postgres=# show block_size; block_size ------------ 32768 (1 row) postgres=#
■テスト環境とデータ
今回テストを行ったのは以下の環境です。
- NEC Express5800 GT110b
- Xeon Intel Xeon X3440 2.53GHz (1P4C)
- Unbeffered ECC 16GB
- Intel 520 Series 180GB
- Hitachi Deskstar 7K1000 HDS72101
- Red Hat Enterprise Linux 6.3 (x86_64)
/dev/mapper/vg_devsv03-lv_root on / type ext4 (rw) /dev/mapper/vg_devsv03-lv_home on /home type ext4 (rw) /dev/sda1 on /disk/disk1 type ext4 (rw,discard)PostgreSQLの設定は、postgresql.confの以下のパラメータのみ変更しています。
shared_buffers = 2048MB wal_buffers = 32MB checkpoint_segments = 128 checkpoint_timeout = 60min autovacuum = off今回、テストで使ったデータは、OSDL DBT-3のスキーマとテストデータです。
テストデータはスケールファクタを「10」として生成しており、データサイズは、ロードする前のCSVファイルで10GB、ロード済みデータベースサイズ(テーブルおよびインデックス)で25GBとなっています。
■データのローディングとインデックスの作成
まず、テーブルへのデータローディングと主キー制約の追加、およびインデックス作成のパフォーマンスを計測します。
対象となるテーブルは以下の8つのテーブルです。
dbt3=# \d+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+-----------------+-------+-------+------------+-------------
public | customer | table | snaga | 276 MB |
public | lineitem | table | snaga | 8324 MB |
public | nation | table | snaga | 8192 bytes |
public | orders | table | snaga | 1979 MB |
public | part | table | snaga | 317 MB |
public | partsupp | table | snaga | 1335 MB |
public | region | table | snaga | 8192 bytes |
public | supplier | table | snaga | 17 MB |
(8 rows)
dbt3=#
テーブルにデータをロードした後、ALTER TABLEコマンドで各テーブルに主キー制約を追加し、かつCREATE INDEXコマンドで15個のインデックスを作成しています。これらの処理を、PostgreSQLのデータブロックをそれぞれ8kBブロック、16kBブロック、32kBブロックに変更したデータベースに対して実行した結果が以下のグラフです。
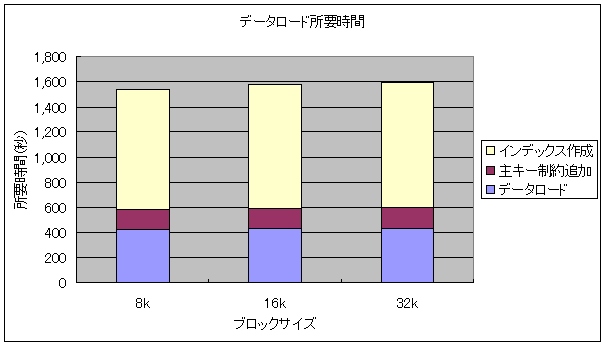
青の部分はテーブルにデータをロードするのに要した時間、紫は主キー制約の追加に要した時間、クリーム色の部分は追加のインデックス作成に要した時間で、積み上げグラフで秒数で表示しています。
このグラフを見ると、データのローディングやインデックスの作成などについては、あまりパフォーマンス上の向上が見られないことが分かります。むしろ、ブロックサイズが8kBの時と比べて、32kBの時にはパフォーマンスが若干低下しています。(全体としてはさほどインパクトはありませんが)
なお、今回は時間の関係上、データのローディングとインデックスの作成については、一回しか計測していません。複数回計測して平均を取る、といった処理は行っていませんので、その点はご承知おきください。
■テーブルフルスキャン
データベースの構築が完了したら、クエリの実行を行ってみます。
まずは、もっとも単純なテーブルのフルスキャンを行います。
select count(*) from lineitem;lineitemテーブルへのcount(*)の処理は、8GB強のテーブルをシーケンシャルスキャンすることになり、実行プランは以下の通りです。
QUERY PLAN
---------------------------------------------------------------------------
Aggregate (cost=1279737.95..1279737.96 rows=1 width=0)
-> Seq Scan on lineitem (cost=0.00..1129772.56 rows=59986156 width=0)
(2 rows)
以下が、ブロックサイズ別のlineitemテーブルへの実行時間(5回平均)です。
これを見るとブロックサイズを8kBから32kBへと大きくするに従ってパフォーマンスが向上しているように見えます。
ブロックサイズを変えることで、本当にこれだけパフォーマンスが向上しているのでしょうか。
その点を確認するために、5回分の実行時間を個別に比較したものが以下のグラフになります。

これを見ると一目瞭然ですが、8kBブロックの場合、1回目から5回目まで実行時間がほとんど変わっていないのに対して、16kBブロックの場合は4回目から、32kBブロックの場合は2回目から実行時間が大幅に短縮されています。
この「実行時間が短くなっていく」理由はまだよく分かっていませんが、少なくとも共有バッファの状態とはあまり関係がないようです。(テスト用のクエリは、PostgreSQLのサービス起動直後、つまり共有バッファが空の状態から5回連続して実行しています)
以下は、lineitemテーブルのフルスキャンを6457.410ミリ秒で実行した時に、lineitemテーブルのブロックは、全1057132ブロックのうち8ブロックしか共有バッファに載っていなかったことを示しています。(呼び出しているrpt_buf_cache.sqlはpg_buffercacheモジュールの値を集計するスクリプトです)
dbt3=# \timing Timing is on. dbt3=# SELECT count(*) FROM lineitem; count ---------- 59986052 (1 row) Time: 6457.410 ms dbt3=# \i rpt_buf_cache.sql name | num_buf | num_blks | pct ----------+---------+----------+------ lineitem | 8 | 1057132 | 0.00 <others> | 46 | | (2 rows) Time: 32.223 ms dbt3=# SHOW block_size ; block_size ------------ 32768 (1 row) Time: 0.223 ms dbt3=#上記の通り、(Day7のエントリで紹介したpg_buffercacheモジュールを使って)共有バッファの状態を確認してみた限り、データブロックがほとんど共有バッファに載っていなくても、lineitemテーブルのフルスキャンを6秒強で実行できています。
よって、PostgreSQLではなくファイルシステムレベルに原因があるのかもしれません。
■GROUP BYによる集約
次に、GROUP BYによる集約処理のパフォーマンスを見てみます。
実行するクエリは以下の通りで、月ごとの注文金額総額を集計しています。
select date_trunc('month', o_orderdate), sum(o_totalprice)
from orders
group by date_trunc('month', o_orderdate)
order by 1;
実行プランは以下の通りです。
QUERY PLAN
----------------------------------------------------------------------------------
Sort (cost=363007.84..363013.85 rows=2406 width=8)
Sort Key: (date_trunc('month'::text, (o_orderdate)::timestamp with time zone))
-> HashAggregate (cost=362836.62..362872.71 rows=2406 width=8)
-> Seq Scan on orders (cost=0.00..287837.71 rows=14999781 width=8)
(4 rows)
実行時間をブロックサイズ別に測定したものが以下のグラフです。
このクエリの場合には、ほとんどパフォーマンスが変わりませんでした。
■結合と集約
最後に、もう少し複雑な結合と集約を含むクエリを実行してみます。
以下は、注文時に約束した期日までに配達が終わらなかった注文について、顧客ごとに集計して多い順に20件ランキングしています。
select o.o_custkey,count(*) from orders o, lineitem l where l.l_commitdate < l.l_receiptdate and l.l_orderkey = o.o_orderkey group by o.o_custkey order by 2 desc limit 20;以下は、上記のクエリのブロックサイズ別の実行時間です(5回平均)。

このクエリもパフォーマンスが向上していますが、最初のlineitemテーブルへのシーケンシャルスキャンの場合と違って、1回目から5回目まで、ブロックサイズに応じて実行時間が短縮されています。

但し、8kBブロック、16kBブロックの時にはHash Joinが使われたのに対して、32kBブロックの時にはMerge Joinが使われる、といった違いがありました。
以下は8kBブロックの時の実行プランです。
QUERY PLAN
--------------------------------------------------------------------------------------------------------
Limit (cost=7004441.17..7004441.22 rows=20 width=4)
-> Sort (cost=7004441.17..7006622.04 rows=872351 width=4)
Sort Key: (count(*))
-> GroupAggregate (cost=6822539.33..6981228.22 rows=872351 width=4)
-> Sort (cost=6822539.33..6872527.79 rows=19995384 width=4)
Sort Key: o.o_custkey
-> Hash Join (cost=649382.08..3304284.73 rows=19995384 width=4)
Hash Cond: (l.l_orderkey = o.o_orderkey)
-> Seq Scan on lineitem l (cost=0.00..1815236.90 rows=19995384 width=4)
Filter: (l_commitdate < l_receiptdate)
-> Hash (cost=403281.59..403281.59 rows=15000359 width=8)
-> Seq Scan on orders o (cost=0.00..403281.59 rows=15000359 width=8)
(12 rows)
以下は32kBブロックの際の実行プランです。
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Limit (cost=4970682.69..4970682.74 rows=20 width=4)
-> Sort (cost=4970682.69..4972685.24 rows=801019 width=4)
Sort Key: (count(*))
-> GroupAggregate (cost=4791392.62..4949367.86 rows=801019 width=4)
-> Sort (cost=4791392.62..4841380.97 rows=19995341 width=4)
Sort Key: o.o_custkey
-> Merge Join (cost=44.76..2093263.54 rows=19995341 width=4)
Merge Cond: (o.o_orderkey = l.l_orderkey)
-> Index Scan using pk_orders on orders o (cost=0.00..328663.08 rows=15000450 width=8)
-> Index Scan using i_l_orderkey on lineitem l (cost=0.00..1477217.99 rows=19995341 width=4)
Filter: (l_commitdate < l_receiptdate)
(11 rows)
■まとめ
今回は、PostgreSQLのデータブロックの変更方法と、ブロックサイズの変更がクエリのパフォーマンス、特に集計系・分析系のクエリにどのような影響を与えるのかを、簡単なクエリを実行しながら見てきました。
今回の実験では、クエリのパフォーマンスが向上した理由、あるいは向上しなかった理由を踏み込んで解明するところまでには至りませんでしたが、もう少し動作を理解した上で、うまくチューニングポイントを見つければ、データ分析のデータベースパフォーマンスを最適化する方法論が見つかるかもしれません。
興味がある方は、ぜひ試してみていただければと思います。私も継続的に調査していきたいと思います。
では、また。
0 件のコメント:
コメントを投稿